Project: Ease.ml
The fundemental hypothesis of ease.ml is that future machine learning platforms should manage the end-to-end process of building ML applications, beyond simplying making training a single model faster and automatic.
What is the right level of abstraction that future ML platforms should provide to its end users in order to unleash the full potential of machine learning to non-ML-experts such as biologists, astronomers, social scientists, or generally non-ML software engineers? We believe that understanding this question is the key to unleash the profound impact of ML to society in the near future. In ease.ml, we are inspired by our experience working with a diverse range of domain experts (See Applications) and our own explorations on distributed scalable learning (See ZipML) -- Our belief is that the usability of a learning system should go beyond performance, scalability, and automation, instead, we should aim at managing the end-to-end process of building ML applications and provide systematic guidelines for an end-user. This view opens up a series of fundamental and challenging problems; and our personal view on many of them lead to the end-to-end ease.ml process.
Ease.ml Journey
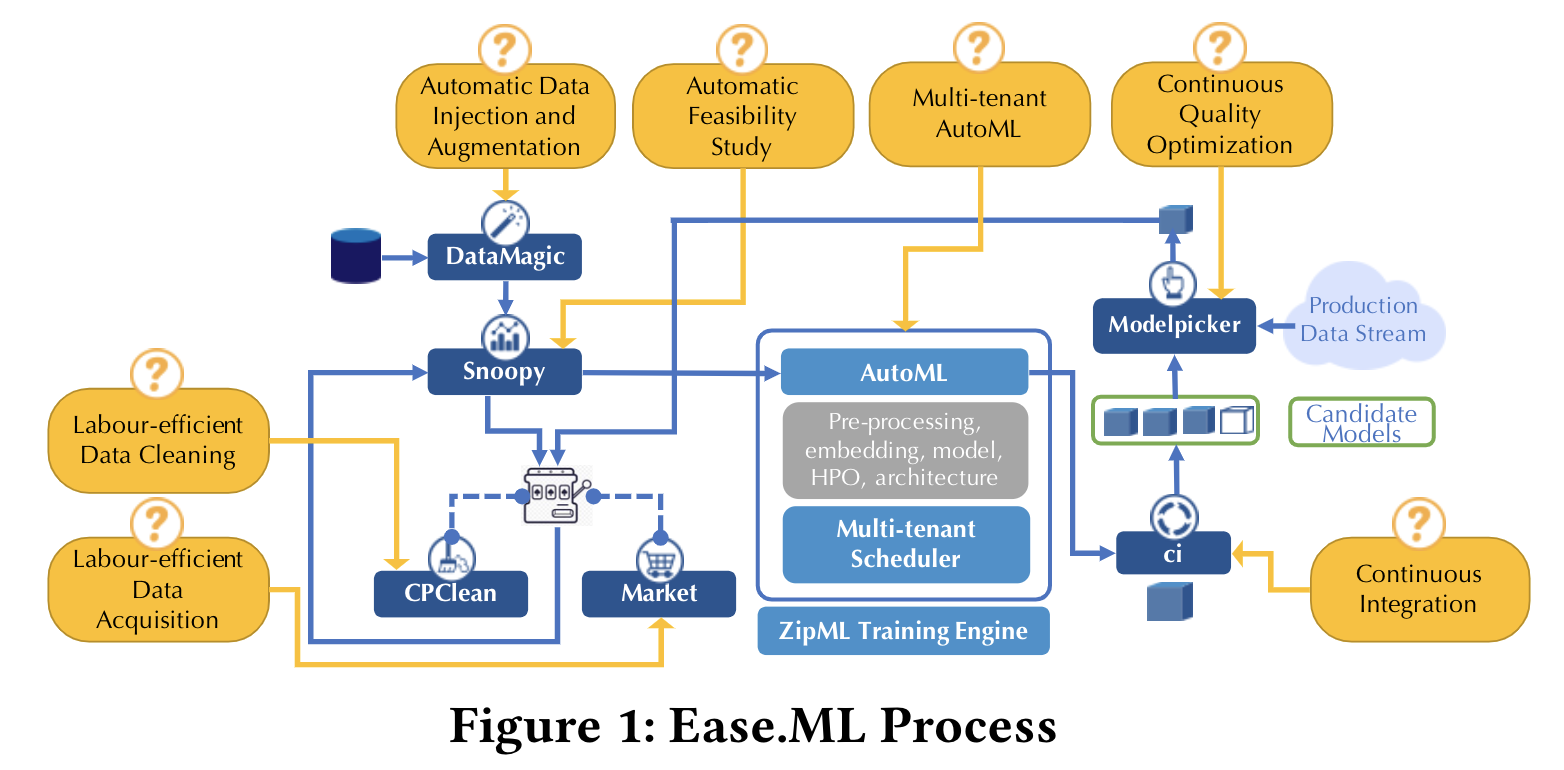
The ease.ml process consists of three stacks -- apart from the standard AutoML stack, the Ease.ml process starts before an ML application is even modelled --- by the Pre-ML Stack --- and finishes at the Post-ML "MLOps" stack. Built as a thin layer over existing data ecosystems and techniques (such as amazing work done by other researchers including Snorkel, Label box, Holocleans, Kubeflow, etc.), ease.ml guides a non-expert user step-by-step: Starting by automatic data ingestion and augmentation (ease.ml/DataMagic), automatic feasibility study (ease.ml/snoopy), data noise debugging (CPClean), data acquisition (Market), scalable multi-tenant automatic training (ease.ml/AutoML), continuous integration (ease.ml/ci), and ending with label-efficient continuous quality optimization (ease.ml/ModelPicker). By following this process, we hope that an end user, without deep understanding of ML techniques, is able to construct ML applications without falling into many common pitfalls (e.g., overfitting, domain drifting, ill-defined tasks or overly noisy datasets).
System Summary Paper
To enable ease.ml, we designed an, in our opinion, interesting schema of our data, model, and the process. For example, uncertainty is a first class citizen in our data model and we enforce a clear separation between four pillars of data: training set, development set, stable test set, and realtime test set. Another example is that we model the data flow in the MLOps cycles as an endless stream of models.
Leonel Aguilar, David Dao, Shaoduo Gan, Nezihe Merve Gurel, Nora Hollenstein, Jiawei Jiang, Bojan Karlas, Thomas Lemmin, Tian Li, Yang Li, Susie Rao, Johannes Rausch, Cedric Renggli, Luka Rimanic, Maurice Weber, Shuai Zhang, Zhikuan Zhao, Kevin Schawinski, Wentao Wu, Ce Zhang. external pageEase.ML: A Lifecycle Management System for Machine Learning. CIDR 2021.
Presentation at CIDR 2021 about Ease.ML:

Overview Papers
1. Leonel Aguilar, David Dao, Shaoduo Gan, Nezihe Merve Gurel, Nora Hollenstein, Jiawei Jiang, Bojan Karlas, Thomas Lemmin, Tian Li, Yang Li, Susie Rao, Johannes Rausch, Cedric Renggli, Luka Rimanic, Maurice Weber, Shuai Zhang, Zhikuan Zhao, Kevin Schawinski, Wentao Wu, Ce Zhang. Ease.ML: A Lifecycle Management System for Machine Learning. CIDR 2021.
2. Cedric Renggli, Luka Rimanic, Nezihe Merve Gurel, Bojan Karlas, Wentao Wu, and Ce Zhang. A Data Quality-Driven View of MLOps. IEEE Data Engineering Bulletin 2021.
Technical Papers
3. Bojan Karlaš, Peng Li, Renzhi Wu, Nezihe Merve Gürel, Xu Chu, Wentao Wu, Ce Zhang. Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions. VLDB 2021.
4. Yang Li, Yu Shen, Wentao Zhang, Jiawei Jiang, Yaliang Li, Bolin Ding, Jingren Zhou, Zhi Yang. Wentao Wu, Ce Zhang, Bin Cui. VolcanoML: Speeding up End-to-End AutoML via Scalable Search Space Decomposition. VLDB 2021.
5. Peng Li, Xi Rao, Jeffinifer Blase, Yue Zhang, Xu Chu, Ce Zhang. CleanML: A Benchmark for Evaluating the Impact of Data Cleaning on ML Classification Tasks. ICDE 2021.
6. Mohammad Reza Karimi*, Nezihe Merve Gürel*, Bojan Karlaš, Johannes Rausch, Ce Zhang, and Andreas Krause. Online Active Model Selection for Pre-trained Classifiers. AISTATS 2021.
7. Ruoxi Jia, Xuehui Sun, Jiacen Xu, Ce Zhang, Bo Li, Dawn Song. An Empirical and Comparative Analysis of Data Valuation with Scalable Algorithms. CVPR 2021.
8. Bojan Karlaš, Matteo Interlandi, Cedric Renggli, Wentao Wu, Ce Zhang, Deepak Mukunthu Iyappan Babu, Jordan Edwards, Chris Lauren, Andy Xu and Markus Weimer. Building Continuous Integration Services for Machine Learning. KDD 2020 (Applied Data Science, Oral Presentation 44/756).
9. Luka Rimanic*, Cedric Renggli*, Bo Li, Ce Zhang. On Convergence of Nearest Neighbor Classifiers over Feature Transformations. NeurIPS 2020.
10. Giuseppe Russo, Nora Hollenstein, Claudiu Musat, Ce Zhang. Control, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation. Findings of EMNLP, 2020.
11. Johannes Rausch, Octavio Martinez, Fabian Bissig, Ce Zhang, Stefan Feuerriegel. DocParser: Hierarchical Structure Parsing of Document Renderings. AAAI, 2020.
12. Yang Li, Jiawei Jiang, Jinyang Gao, Yingxia Shao, Ce Zhang, Bin Cui. Efficient Automatic CASH via Rising Bandits. AAAI 2020.
13. Yujing Wang, Yaming Yang, Yiren Chen, Jing Bai, Ce Zhang, Guinan Su, Xiaoyu Kou, Yunhai Tong, Mao Yang, Lidong Zhou. TextNAS: A Neural Architecture Search Space tailored for Text Representation. AAAI 2020.
14. Ruoxi Jia, David Dao, Boxin Wang, Frances A. Hubis, Nick Hynes, Nezihe M. Gürel, Bo Li, Ce Zhang, Dawn Song and Costas J. Spanos. Towards Efficient Data Valuation Based on the Shapley Value. AISTATS 2019.
15. Ruoxi Jia, David Dao, Boxin Wang, Frances A. Hubis, Nezihe M. Gürel, Bo Li, Ce Zhang, Costas J. Spanos and Dawn Song. Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms. VLDB 2019.
16. Cedric Renggli, Bojan Karlas, Bolin Ding, Feng Liu, Kevin Schawinski, Wentao Wu, Ce Zhang. Continuous Integration of Machine Learning Models: A Rigorous Yet Practical Treatment. SysML 2019.
17. Yu Chen, Bojan Karlaš, Jie Zhong, Ce Zhang and Ji Liu. AutoML from Service Provider’s Perspective: Multi-device, Multi-tenant Model Selection with GP-EI. AISTATS 2019.
18. Tian Li, Jie Zhong, Ji Liu, Wentao Wu and Ce Zhang. Ease.ml: towards multi-tenant resource sharing for machine learning workloads. VLDB 2018.
Demos
19. Cedric Renggli*, Luka Rimanic*, Luka Kolar, Wentao Wu, Ce Zhang. Ease.ml/snoopy in Action: Towards Automatic Feasibility Analysis for Machine Learning Application Development. VLDB Demo 2020.
20. Cedric Renggli*, Frances Ann Hubis*, Bojan Karlaš, Kevin Schawinski, Wentao Wu, Ce Zhang. Ease.ml/ci and Ease.ml/meter in Action: Towards Data Management for Statistical Generalization. VLDB Demo 2019.
21. Bojan Karlaš, Ji Liu, Wentao Wu and Ce Zhang. Ease.ml in Action: Towards Multi-tenant Declarative Learning Services. VLDB Demo 2018.
Pre-prints
22. Cedric Renggli*, Luka Rimanic*, Luka Kolar*, Nora Hollenstein, Wentao Wu, Ce Zhang. On Automatic Feasibility Study for Machine Learning Application Development with ease.ml/snoopy. arXiv:2010.08410, 2020.
Ease.ml/DataMagic
Modern ML applications are often data hungry --- sometimes it is caused by the extensive process of data collection, and sometimes it is caused by the striking diversity of the data format that makes it hard to construct a homogeneous large dataset. Given an input dataset from the user, the first step of the ease.ml process, ease.ml/DataMagic, aims at providing functionalities of automatic data augmentation (adding new data examples automatically) and automatic data ingestion (automatically normalizing data into the same, machine readable, format).
The current version of ease.ml/DataMagic focuses on the NLP domain. For data augmentation, we designed a novel framework of automatic style transfer for natural language text (e.g., passive to active voice). For data ingestion, we designed a robust system, based on a novel weak supervision technique, to automatically parse documents in different formats (e.g., PDFs, Word, scanned documents, etc.) to machine readable JSON objects.
Input: Input dataset with labels.
Output: Augmented, machine readable, dataset with labels.
Publications
Giuseppe Russo, Nora Hollenstein, Claudiu Musat, Ce Zhang. Control, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation. Findings of EMNLP, 2020.
Johannes Rausch, Octavio Martinez, Fabian Bissig, Ce Zhang, Stefan Feuerriegel. DocParser: Hierarchical Structure Parsing of Document Renderings. AAAI, 2020.
Ease.ml/snoopy
Machine learning is no panacea --- if your data are 20% wrong but you are hoping for 90% accuracy to make a profit out of your model, it is highly likely that it is doomed to fail. In our experience, we were surprised by how often an end user has a staggering mismatch between the quality of their data an the expectation of the accuracy that an ML model can achieve.
Our view to this problem is to provide the functionality of an automatic feasibility study to the end user --- given a dataset and an target accuracy, we provide the user a best-effort "belief" on whether it is possible or not, before the users fire up expensive ML processes, just like how many real-world ML consultants are dealing with their customers. Of course, such a "belief" will never be perfect, but we hope that providing such a signal will help the end users to better calibrate their expectations.
From the technical perspective, what we are estimating is the Bayes error, a fundamental ML concept. In ease.ml/snoopy, we designed a simple, yet effective, Bayes error estimator enabled by the recent advancement of representation learning and the increasing availability of pre-trained feature embeddings.
Input: (1) Augmented, machine readable, dataset; (2) Target accuracy.
Output: {Feasible, Not Feasible} as the belief of the system.
Action: (1) If "Feasible", proceeds to ease.ml/AutoML; (2) If "Not Feasible", proceeds to CPClean.
Project Page
Publications
Cedric Renggli*, Luka Rimanic*, Luka Kolar*, Nora Hollenstein, Wentao Wu, Ce Zhang. On Automatic Feasibility Study for Machine Learning Application Development with ease.ml/snoopy. arXiv:2010.08410, 2020.
Luka Rimanic*, Cedric Renggli*, Bo Li, Ce Zhang. On Convergence of Nearest Neighbor Classifiers over Feature Transformations. NeurIPS 2020.
Cedric Renggli*, Luka Rimanic*, Luka Kolar, Wentao Wu, Ce Zhang. Ease.ml/snoopy in Action: Towards Automatic Feasibility Analysis for Machine Learning Application Development. VLDB Demo 2020.
CPClean/DataScope
What if ease.ml/snoopy thinks your data is not good enough for ML to reach your quality target? In this case, it might be counterproductive to fire up an expensive ML training process, instead, we hope to help the user to understand their data better and make a more informative decision.
In ease.ml, our belief (which of course is far off from perfect) is that there are two key reasons behind an unsatisfactory quality --- (1) the existing data is too noisy and we need to clean it up, and (2) the existing dataset is too small and we need to acquire more.
CPClean tries to provide insights on the impact of data noises to the trained ML model. In principle, it asks the following question --- given a noise distribution on each data value (which can be constructed using an ensemble of state-of-the-art data cleaning tools), what's the highest possible accuracy that an ML model can achieve? This value will provide the user more insights on what to do --- if such an accuracy is high enough, the user should conduct data cleaning using state-of-the-art techniques; otherwise, data cleaning might simply be a waste of efforts an the users are probably better off acquiring more data.
The technical challenge here is that there are exponentially many possible combinations of noisy values and how can we find the one with best ML accuracy? We show that, surprisingly, for k-nearest neighbour classifiers, this problem can be solved in polynomial (and sometimes linear) time! By using a k-nearest neighbour classifier as a proxy, CPClean provides users the signal corresponding to the potential of data cleaning.
As a by-product, there is an interesting connection between CPClean and robustness (especially randomised smoothing). We show that it is possible to extend the idea behind CPClean to provide the first provably robust defence to backdoor attacks.
Input: Augmented, machine readable, dataset.
Output: The system's belief on the best possible KNN accuracy after data cleaning.
Action: (1) If the potential is high, proceeds to state-of-the-art data cleaning tools and rerun the loop starting from ease.ml/DataMagic; (2) If the potential is low, proceeds to Market to acquire more data.
Publications
Bojan Karlaš, Peng Li, Renzhi Wu, Nezihe Merve Gürel, Xu Chu, Wentao Wu, Ce Zhang. Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions. VLDB 2021.
Peng Li, Xi Rao, Jeffinifer Blase, Yue Zhang, Xu Chu, Ce Zhang. CleanML: A Benchmark for Evaluating the Impact of Data Cleaning on ML Classification Tasks. ICDE 2021.
DataScope
If data cleaning won't increase your accuracy by too much, another potential reason of unsatisfactory ML quality is simply that you don't have enough amount of data. If CPClean advices the user against data cleaning, she needs to acquire more data. Market is the next ease.ml component that helps the user with this.
We focus on a specific case of data acquisition --- given a pool of data examples, how can we choose which one to include (and to label if they are unlabelled) to maximize the accuracy of ML models? In principle, we hope to pick out those data examples that are more "valuable" to the downstream ML models.
In Market, we decide whether a data example is valuable by using the Shapley value, a well established concept in game theory, and treat the accuracy of ML models as the utility. Unfortunately, simply evaluating the Shapley value can be expensive --- for generic ML models, it is exponential to the number of data examples. Fortunately, we show that, for k-nearest neighbour classifiers, calculating the exact Shapley value can be done in nearly linear time! In Market, we use the k-nearest neighbour classifiers as a proxy and provide the guidance for the user on which new data samples to acquire.
Input: (1) Augmented, machine readable, dataset; (2) A pool of potential data examples that one can acquire.
Output: The system's belief on the value of each potential data example for the user to acquire.
Action: The user acquire more data and rerun the loop starting from ease.ml/DataMagic.
Publications
Ruoxi Jia, David Dao, Boxin Wang, Frances A. Hubis, Nick Hynes, Nezihe M. Gürel, Bo Li, Ce Zhang, Dawn Song and Costas J. Spanos. Towards Efficient Data Valuation Based on the Shapley Value. AISTATS 2019.
Ruoxi Jia, David Dao, Boxin Wang, Frances A. Hubis, Nezihe M. Gürel, Bo Li, Ce Zhang, Costas J. Spanos and Dawn Song. Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms. VLDB 2019.
Ruoxi Jia, Xuehui Sun, Jiacen Xu, Ce Zhang, Bo Li, Dawn Song. An Empirical and Comparative Analysis of Data Valuation with Scalable Algorithms. CVPR 2021.
Ease.ml/AutoML
If ease.ml/snoopy said "Yes" and we can finally fire up our ML training process! Given a dataset, ease.ml contains an AutoML component that outputs a ML model without any user intervention. There are three aspects of ease.ml/AutoML that makes it special.
The first aspect is that it is holistic --- we aim at fully automate the end-to-end process of building ML applications, from feature engineering, model selection, architecture search, hyper-parameter tuning, and post-processing. Our system is built upon many seminal work for each of these sub-process, while also contains our own techniques and algorithms.
The second aspect is that it is multi-tenant and scalable --- different from many existing ML platforms in which users are isolated, the view of ease.ml/AutoML is that AutoML is an endless process: whenever a new model architecture has been published by researcher, all users' application should be reran! This view introduced a scalability problem and ease.ml/AutoML tries to handle this process by having multiple users sharing multiple devices. Those users who have the highest potential to better accuracies should occupy proportionally more devices. This opens up an interesting research problem about resource sharing and allocations for AutoML workloads, and we develop an interesting principled algorithm for this problem.
The third aspect is rooted in our belief that many future ML workloads can be solved by simply applying a transfer learning-based approach. Together with the increasing availability of pre-trained ML models (via repositories such as TensorFlow Hub and Pytorch Hub), this aspect becomes increasingly promising, while how to efficiently manage such large pools of pre-trained models also becomes an emerging problem.
Input: (1) Augmented, machine readable, dataset;
Output: An endless stream of models trained by the AutoML system.
Publications
Yang Li, Yu Shen, Wentao Zhang, Jiawei Jiang, Yaliang Li, Bolin Ding, Jingren Zhou, Zhi Yang. Wentao Wu, Ce Zhang, Bin Cui. VolcanoML: Speeding up End-to-End AutoML via Scalable Search Space Decomposition. VLDB 2021.
Yu Chen, Bojan Karlaš, Jie Zhong, Ce Zhang and Ji Liu. AutoML from Service Provider’s Perspective: Multi-device, Multi-tenant Model Selection with GP-EI. AISTATS 2019.
Tian Li, Jie Zhong, Ji Liu, Wentao Wu and Ce Zhang. Ease.ml: towards multi-tenant resource sharing for machine learning workloads. VLDB 2018.
Bojan Karlaš, Ji Liu, Wentao Wu and Ce Zhang. Ease.ml in Action: Towards Multi-tenant Declarative Learning Services. VLDB Demo 2018.
Yang Li, Jiawei Jiang, Jinyang Gao, Yingxia Shao, Ce Zhang, Bin Cui. Efficient Automatic CASH via Rising Bandits. AAAI 2020.
Yujing Wang, Yaming Yang, Yiren Chen, Jing Bai, Ce Zhang, Guinan Su, Xiaoyu Kou, Yunhai Tong, Mao Yang, Lidong Zhou. TextNAS: A Neural Architecture Search Space tailored for Text Representation. AAAI 2020.
Ease.ml/ci
Machine learning models are software artefacts. Among the stream of models generated by ease.ml/AutoML, not all of them satisfy the based requirement of real-world deployment. Can we continuously test ML models in the way we are testing traditional softwares?
Ease.ml/ci is a continuous integration engine developed for ML. Given a new machine learning model committed into the system, and a set of user-specified conditions and test dataset (e.g., the new model is at least 1 points better than the old model), ease.ml/ci checks whether the given model satisfies all the test conditions.
One technical challenge is overfitting --- after every test query, the test set will lose some of its statistical power. If we are not being careful, after a while, we are going to overfit to the provided test set and ease.ml/ci would potentially return a wrong answer. The technical core of ease.ml/ci is a collection of techniques to measure the "information leakage" coming along with each test query, and inform the user when a new test dataset is required.
Input: (1) An endless stream of models trained by the AutoML system; (2) A test set and a list of test conditions.
Output: An endless stream of models, each of which is labelled by {Pass, Failure}.
Action: The user has to provide a new test set when ease.ml/ci requests so.
Publications
Cedric Renggli, Bojan Karlas, Bolin Ding, Feng Liu, Kevin Schawinski, Wentao Wu, Ce Zhang. Continuous Integration of Machine Learning Models: A Rigorous Yet Practical Treatment. SysML 2019.
Bojan Karlaš, Matteo Interlandi, Cedric Renggli, Wentao Wu, Ce Zhang, Deepak Mukunthu Iyappan Babu, Jordan Edwards, Chris Lauren, Andy Xu and Markus Weimer. Building Continuous Integration Services for Machine Learning. KDD 2020 (Applied Data Science, Oral Presentation 44/756).
Cedric Renggli*, Frances Ann Hubis*, Bojan Karlaš, Kevin Schawinski, Wentao Wu, Ce Zhang. Ease.ml/ci and Ease.ml/meter in Action: Towards Data Management for Statistical Generalization. VLDB Demo 2019.
Ease.ml/ModelPicker
All models that pass ease.ml/ci, in principle, can be deployed. This gives a pool of candidate models at any given time, each of which can be developed under different hypotheses (e.g., different slices of data). While real-world data distribution keeps changing rapidly (e.g., every day), how can we pick the best model, i.e. the one that fits our latest data distribution?
Our view is to enable a rapid MLOps loop: every day (hour), real-world (unlabelled) data comes into the system, and an MLOps engineer would label these fresh data to pick the best model to use for the coming day (hour), from the pool of candidate models. The key technical challenge is to decrease the number of labels required from the MLOps engineer to control the cost of such a process.
In ease.ml/ModelPicker, we designed a novel active learning algorithm which picks the most "informative" data points for an MLOps engineer to label. With our algorithm, we can pick the best out of 102 models over ImageNet, with merely ~1K images to label!
Input: (1) A set of models, each of which passed ease.ml/ci; (2) a fresh unlabelled test set.
Output: The model with highest test accuracy.
Action: The user provides labels on data examples picked by ease.ml/ModelPicker. Deploy the picked model until a new fresh unlabelled test set comes.
Publications
Mohammad Reza Karimi*, Nezihe Merve Gürel*, Bojan Karlaš, Johannes Rausch, Ce Zhang, and Andreas Krause. Online Active Model Selection for Pre-trained Classifiers. AISTATS 2021.