Project: Zip.ml
Scalable systems and the rapid improvement of computation capacities are key factors that fuel the recent advancement of AI. Zip.ML aims to further push the boundary, focusing on the co-design of ML algorithms, data ecosytems, and hardware acceleration.
Specifically, we focus on two questions:
- How can we co-design both the algorithm and the hardware to fully unleash the potential on both side?
- How can we efficiently integrate ML into existing data ecosystems such as database systems, serverless environments, Spark?
Zip.ml aims at answering these questions, with a jointly endeavor on both ML algorithm, data system, and hardware acceleration.
Zip.ml contains four threads of research:
1. Theoretical Foundations: How much flexibility do we have in designing ML algorithms while maintaining the final model quality? What is our fundamental limitations and tradeoffs?
2. Distributed Learning: How to construct scalable ML systems? How to take advantage of theoretical understandings on the flexibility?
3. ML Integration in data ecosystems: How to efficiently integrate ML into data ecosystems such as database systems, and serverless environments? How to co-design the ML algorithm, data system, and hardware?
4. Hardware Acceleration: How to design hardware acceleration solutions to further improve the performance?
Overview Papers
1. (Theory) Ji Liu, Ce Zhang. Distributed Learning Systems with First-Order Methods. (Foundations and Trends® in Databases series) 2020.
2. (System) Shaoduo Gan, Xiangru Lian, Rui Wang, Jianbin Chang, Chengjun Liu, Hongmei Shi, Shengzhuo Zhang, Xianghong Li, Tengxu Sun, Jiawei Jiang, Binhang Yuan, Sen Yang, Ji Liu, Ce Zhang. BAGUA: Scaling up Distributed Learning with System Relaxations. external pagehttps://arxiv.org/abs/2107.01499
Technical Papers
3. Jiawei Jiang*, Shaoduo Gan*, Yue Liu, Fanlin Wang, Gustavo Alonso, Ana Klimovic, Ankit Singla, Wentao Wu, Ce Zhang. Towards Demystifying Serverless Machine Learning Training. SIGMOD 2021.
4. Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, Samyam Rajbhandari, Conglong Li, Xiangru Lian, Ji Liu, Ce Zhang, Yuxiong He. 1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed. ICML 2021.
5. Wenqi Jiang, Zhenhao He, Shuai Zhang, Kai Zeng, Liang Feng, Jiansong Zhang, Tongxuan Liu, Yong Li, Jingren Zhou, Ce Zhang, Gustavo Alonso. FleetRec: Large-Scale Recommendation Inference on Hybrid GPU-FPGA Clusters. KDD (Applied Data Science) 2021.
6. Wenqi Jiang, Zhenhao He, Thomas B. Preußer, Shuai Zhang, Kai Zeng, Liang Feng, Jiansong Zhang, Tongxuan Liu, Yong Li, Jingren Zhou, Ce Zhang, and Gustavo Alonso. Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data StructureSolutions. MLSys 2021.
7. Nezihe Merve Gürel, Kaan Kara, Alen Stojanov, Tyler Smith, Thomas Lemmin, Dan Alistarh, Markus Püschel and Ce Zhang. Compressive Sensing Using Iterative Hard Thresholding with Low Precision Data Representation: Theory and Applications. IEEE Transactions on Signal Processing 2020.
8. Fangcheng Fu, Yuzheng Hu, Yihan He, Jiawei Jiang, Yingxia Shao, Ce Zhang, Bin Cui. Don’t Waste Your Bits! Squeeze Activations and Gradients for Deep Neural Networks via TinyScript. ICML 2020.
9. Zhipeng Zhang, Wentao Wu, Jiawei Jiang, Lele Yu, Bin Cui, Ce Zhang. ColumnSGD: A Column-oriented Framework for Distributed Stochastic Gradient Descent. ICDE 2020.
10. Yunyan Guo, Zhipeng Zhang, Jiawei Jiang, Wentao Wu, Ce Zhang, Bin Cui, Jianzhong Li. Model Averaging in Distributed Machine Learning: A Case Study with Apache Spark. VLDB Journal 2020.
11. Kaan Kara, Ken Eguro, Ce Zhang, Gustavo Alonso. ColumnML: Column-Store Machine Learning with On-The-Fly Data Transformation. VLDB 2019.
12. Zeke Wang, Kaan Kara, Hantian Zhang, Gustavo Alonso, Onur Mutlu, and Ce Zhang. Accelerating Generalized Linear Models with MLWeaving: A One-Size-Fits-All System for Any-precision Learning. VLDB 2019.
13. Chen Yu, Hanlin Tang, Cedric Renggli, Simon Kassing, Ankit Singla, Dan Alistarh, Ce Zhang, Ji Liu. Distributed Learning over Unreliable Networks. ICML 2019.
14. Zhipeng Zhang, Bin Cui, Wentao Wu, Ce Zhang, Lele Yu, Jiawei Jiang. MLlib*: Fast Training of GLMs using Spark MLlib. ICDE 2019.
15. Hanlin Tang, Shaoduo Gan, Ce Zhang, Ji Liu. Communication Compression for Decentralized Training. NeurIPS 2018.
16. Hanlin Tang, Xiangru Lian, Ming Yan, Ce Zhang, Ji Liu. D2: Decentralized Training over Decentralized Data. ICML 2018.
17. X Lian, W Zhang, C Zhang, J Liu. Asynchronous Decentralized Parallel Stochastic Gradient Descent. ICML 2018.
18. H Guo, K Kara, C Zhang. Layerwise Systematic Scan: Deep Boltzmann Machines and Beyond. AISTATS 2018.
19. D Grubic, L Tam, D Alistarh, C Zhang. Synchronous Multi-GPU Deep Learning with Low-Precision Communication: An Experimental Study. EDBT 2018.
20. X Lian, C Zhang, H Zhang, CJ Hsieh, W Zhang, J Liu. Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent. NIPS 2017. (Oral Presentation: 40/3240 submissions)
21. H Zhang, J Li, K Kara, D Alistarh, J Liu, C Zhang. The ZipML Framework for Training Models with End-to-End Low Precision: The Cans, the Cannots, and a Little Bit of Deep Learning. ICML 2017.
22. J Jiang, B Cui, C Zhang, L Yu. Heterogeneity-aware distributed parameter servers. SIGMOD 2017.
23. K M Owaida, H Zhang, G Alonso, C Zhang. Scalable Inference of Decision Tree Ensembles: Flexible Design for CPU-FPGA Platforms. FPL 2017.
24.K Kara, D Alistarh, G Alonso, O Mutlu, C Zhang. FPGA-accelerated Dense Linear Machine Learning: A Precision-Convergence Trade-off. FCCM 2017.
Demos
25. Kaan Kara, Zeke Wang, Gustavo Alonso, Ce Zhang. doppioDB 2.0: Hardware Techniques for Improved Integration of Machine Learning into Databases. VLDB Demo 2019.
1. Theoretical Foundation
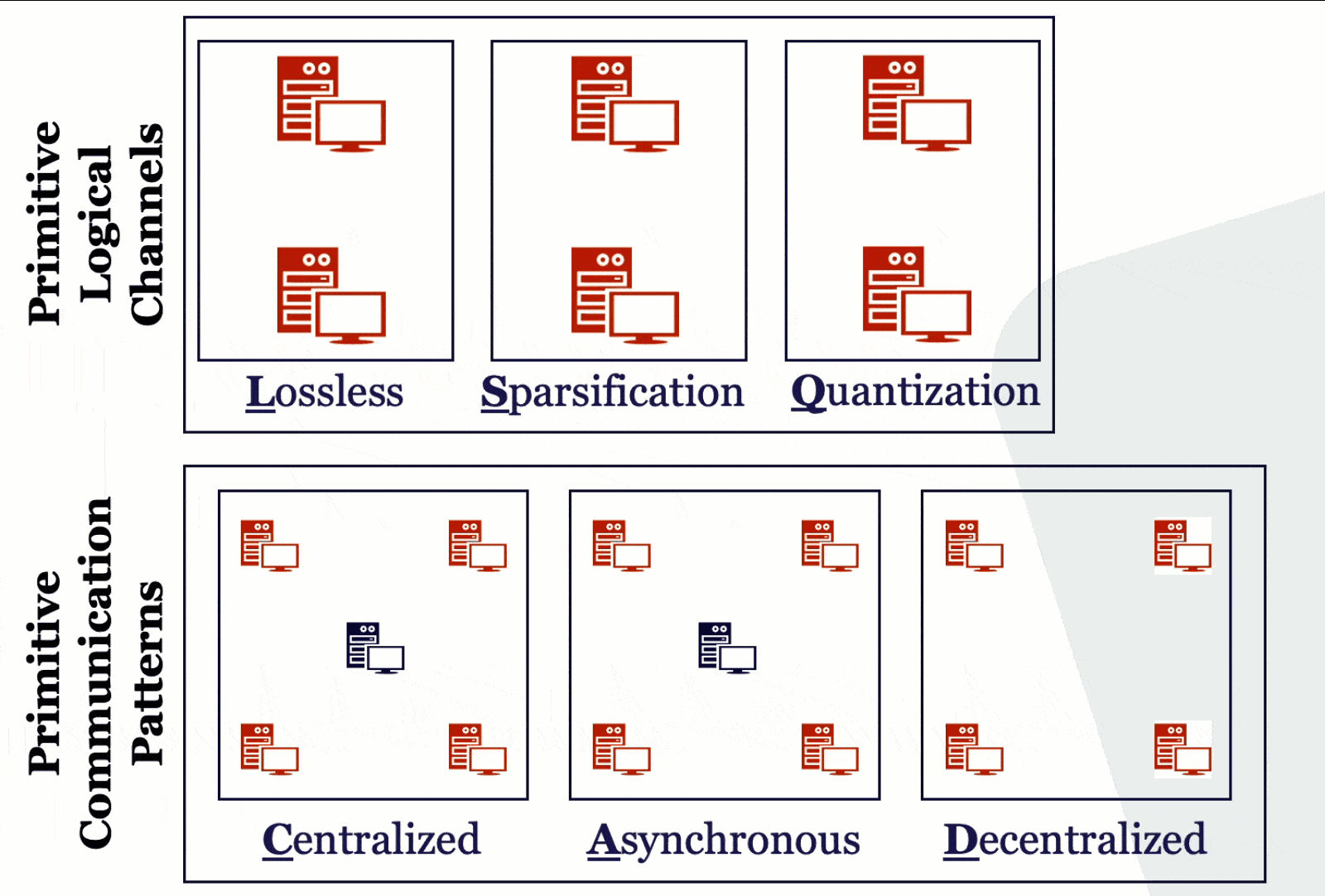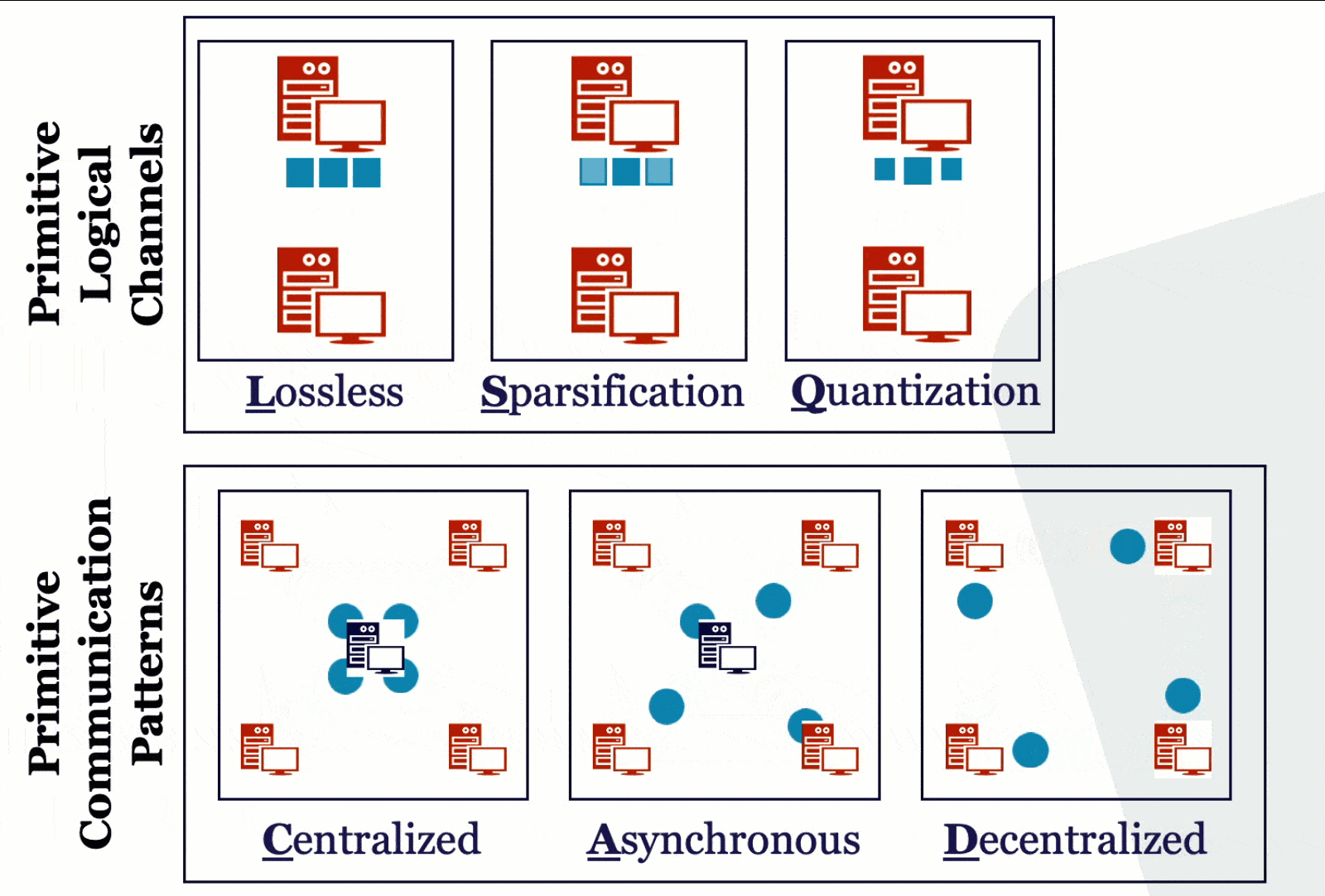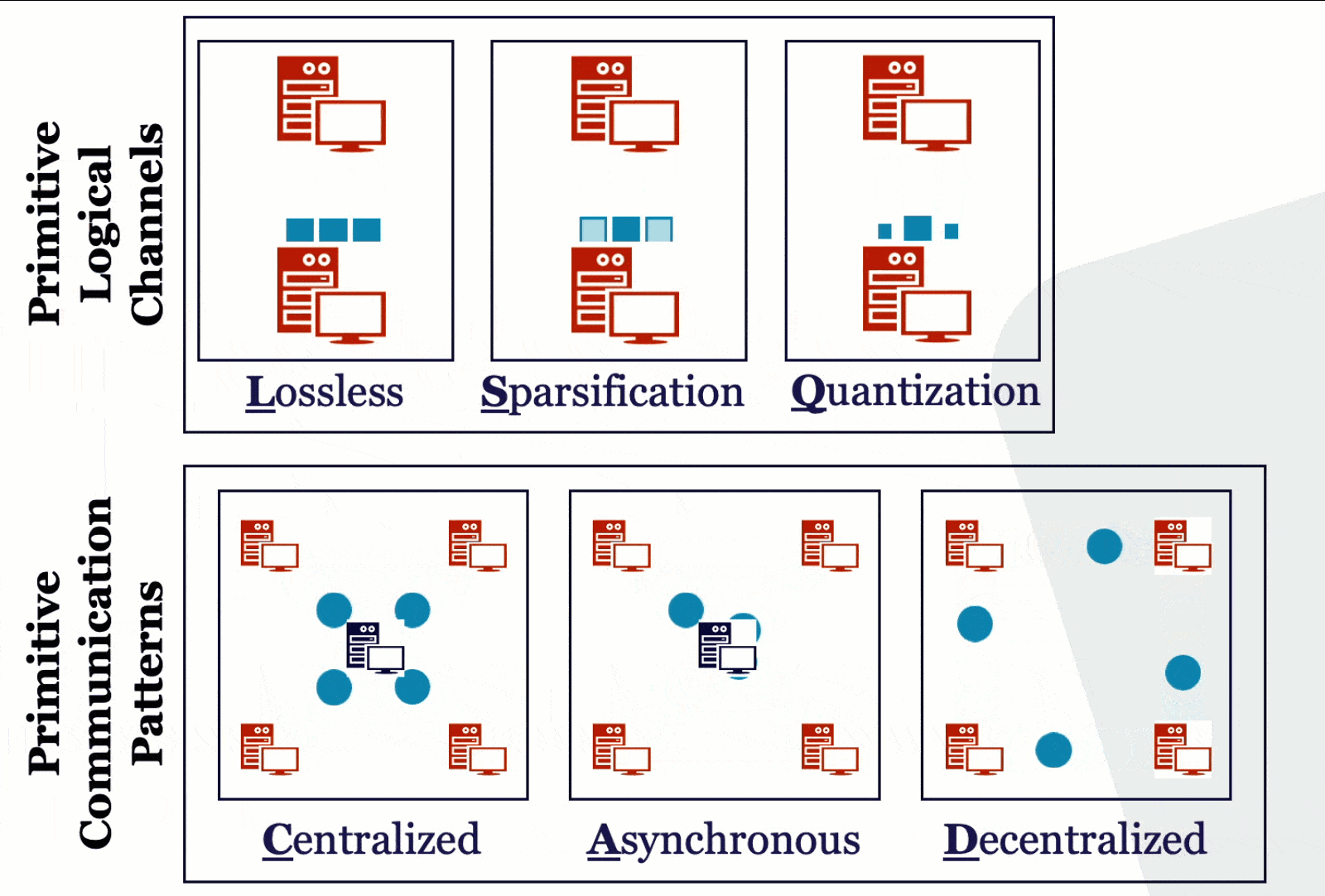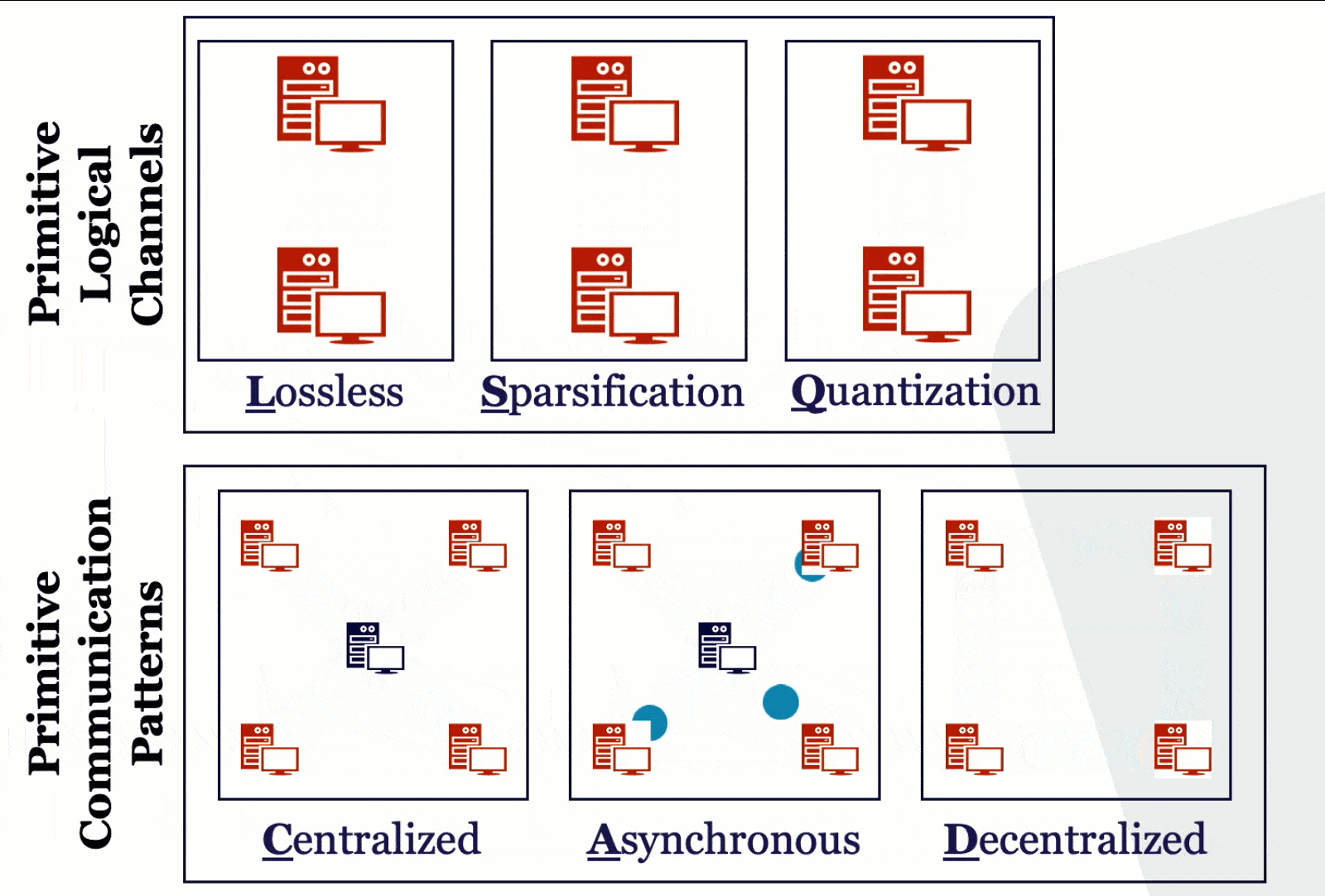
How should different machines communicate in distributed learning? We study this question in a principled way, understanding the theoretical properties of different system relaxation techniques such as gradient compression, asynchronous computations, decentralized computations, data compression. Via a systematic way, we design efficient algorithms with rigorous theoretical analysis for each of these different scenarios and their combinations. Our exploration forms the basis for us to understand different design decisions of scalable and efficient ML systems.

external pageDistributed Learning Systems with First Order Methods
In this monograph (external pageFoundations and Trends® in Databases series), we summarize the theoretical foundation of the Zip.ml project: system relaxation techniques for distributed learning, such as lossy communication compression, decentralization, and asynchronization. In Zip.ml, we combine these theoretical results together with carefully designed ecosytem (e.g., DB, Spark, FaaS) specific optimizations and the power of modern hardware (e.g., FPGAs).
Free Version: DownloadHere (PDF, 2.2 MB)
Publications
Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, Samyam Rajbhandari, Conglong Li, Xiangru Lian, Ji Liu, Ce Zhang, Yuxiong He. 1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed. ICML 2021.
Nezihe Merve Gürel, Kaan Kara, Alen Stojanov, Tyler Smith, Thomas Lemmin, Dan Alistarh, Markus Püschel and Ce Zhang. Compressive Sensing Using Iterative Hard Thresholding with Low Precision Data Representation: Theory and Applications. IEEE Transactions on Signal Processing 2020.
Fangcheng Fu, Yuzheng Hu, Yihan He, Jiawei Jiang, Yingxia Shao, Ce Zhang, Bin Cui. Don’t Waste Your Bits! Squeeze Activations and Gradients for Deep Neural Networks via TinyScript. ICML 2020.
Chen Yu, Hanlin Tang, Cedric Renggli, Simon Kassing, Ankit Singla, Dan Alistarh, Ce Zhang, Ji Liu. Distributed Learning over Unreliable Networks. ICML 2019.
Hanlin Tang, Shaoduo Gan, Ce Zhang, Ji Liu. Communication Compression for Decentralized Training. NeurIPS 2018.
Hanlin Tang, Xiangru Lian, Ming Yan, Ce Zhang, Ji Liu. D2: Decentralized Training over Decentralized Data. ICML 2018.
X Lian, W Zhang, C Zhang, J Liu. Asynchronous Decentralized Parallel Stochastic Gradient Descent. ICML 2018.
H Guo, K Kara, C Zhang. Layerwise Systematic Scan: Deep Boltzmann Machines and Beyond. AISTATS 2018.
X Lian, C Zhang, H Zhang, CJ Hsieh, W Zhang, J Liu. Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent. NIPS 2017. (Oral Presentation: 40/3240 submissions)
H Zhang, J Li, K Kara, D Alistarh, J Liu, C Zhang. The ZipML Framework for Training Models with End-to-End Low Precision: The Cans, the Cannots, and a Little Bit of Deep Learning. ICML 2017.
J Jiang, B Cui, C Zhang, L Yu. Heterogeneity-aware distributed parameter servers. SIGMOD 2017.
2. Distributed Deep Learning Systems
Bagua enables a diverse set of communication patterns (e.g., decentralized low precision communication) by providing MPI-style communication primitives. The technical core of Bagua is an automatic optimizer that automatically batch and schedule communications and computations. This allows Bagua to support state-of-the-art training algorithms beyond DP-SGD, outperforming existing systems such as Horovod, BytePS, and Torch-DDP.
Developed together with Kuaishou Inc., Bagua is an open source system: external pagehttp://github.com/BaguaSys/bagua
Overview Paper: external pagehttps://arxiv.org/abs/2107.01499
Invited talk at ISC-HPC 2021 about Bagua:

3. Machine Learning Integration in Data Ecosystems
How can we efficiently integrate ML into exsiting data ecosystems? This question is challenging as one has to respect the constraints set by different ecosystems carefully. How to enable principled integration when we cannot shuffle data easily in database systems or when we cannot communicate between different workers in a serverless environment? How to design novel data layouts for in-database ML? How to take advantage of modern hardwares to make this happen?
Ecosystem 1. Serverless
LambdaML is a system for running ML training in serverless environments. It is open sourced at external pagehttps://github.com/DS3Lab/LambdaML
Publications
Jiawei Jiang*, Shaoduo Gan*, Yue Liu, Fanlin Wang, Gustavo Alonso, Ana Klimovic, Ankit Singla, Wentao Wu, Ce Zhang. Towards Demystifying Serverless Machine Learning Training. SIGMOD 2021.
Ecosystem 2. Databases
Publications
Kaan Kara, Ken Eguro, Ce Zhang, Gustavo Alonso. ColumnML: Column-Store Machine Learning with On-The-Fly Data Transformation. VLDB 2019.
Zeke Wang, Kaan Kara, Hantian Zhang, Gustavo Alonso, Onur Mutlu, and Ce Zhang. Accelerating Generalized Linear Models with MLWeaving: A One-Size-Fits-All System for Any-precision Learning. VLDB 2019.
Kaan Kara, Zeke Wang, Gustavo Alonso, Ce Zhang. doppioDB 2.0: Hardware Techniques for Improved Integration of Machine Learning into Databases. VLDB Demo 2019.
Ecosystem 3. Spark
Publications
Zhipeng Zhang, Wentao Wu, Jiawei Jiang, Lele Yu, Bin Cui, Ce Zhang. ColumnSGD: A Column-oriented Framework for Distributed Stochastic Gradient Descent. ICDE 2020.
Yunyan Guo, Zhipeng Zhang, Jiawei Jiang, Wentao Wu, Ce Zhang, Bin Cui, Jianzhong Li. Model Averaging in Distributed Machine Learning: A Case Study with Apache Spark. VLDB Journal 2020.
Zhipeng Zhang, Bin Cui, Wentao Wu, Ce Zhang, Lele Yu, Jiawei Jiang. MLlib*: Fast Training of GLMs using Spark MLlib. ICDE 2019.
4. Machine Learning meets Hardware Acceleration
Publications
Wenqi Jiang, Zhenhao He, Shuai Zhang, Kai Zeng, Liang Feng, Jiansong Zhang, Tongxuan Liu, Yong Li, Jingren Zhou, Ce Zhang, Gustavo Alonso. FleetRec: Large-Scale Recommendation Inference on Hybrid GPU-FPGA Clusters. KDD (Applied Data Science) 2021.
Wenqi Jiang, Zhenhao He, Thomas B. Preußer, Shuai Zhang, Kai Zeng, Liang Feng, Jiansong Zhang, Tongxuan Liu, Yong Li, Jingren Zhou, Ce Zhang, and Gustavo Alonso. Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data StructureSolutions. MLSys 2021.
D Grubic, L Tam, D Alistarh, C Zhang. Synchronous Multi-GPU Deep Learning with Low-Precision Communication: An Experimental Study. EDBT 2018.
K M Owaida, H Zhang, G Alonso, C Zhang. Scalable Inference of Decision Tree Ensembles: Flexible Design for CPU-FPGA Platforms. FPL 2017.
K Kara, D Alistarh, G Alonso, O Mutlu, C Zhang. FPGA-accelerated Dense Linear Machine Learning: A Precision-Convergence Trade-off. FCCM 2017.